
The Enterprise Data Warehouse built using Teradata, Oracle, DB2 or other DBMS is undergoing a revolutionary change. As the sources of data become rich and diverse, storing them in a traditional EDW is not the optimal solution.
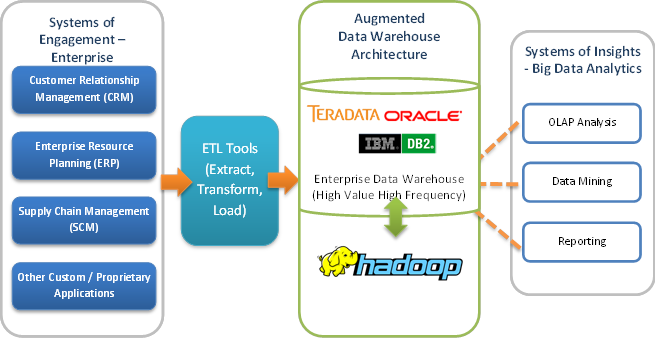
The figure below shows the structure of a typical enterprise data warehouse. Data from various IT applications such as CRM, ERP and Supply Chain Management is fed into a data warehouse by applying appropriate ETL processes to transform it to the desired schema. After aggregation, the results are accessible by end users via Business Intelligence and Reporting tools.
Challenges with Proprietary Data Warehouse Platforms:
- Inefficient resource utilization with ETL, apps and analytics requirements compete with each other
- Incapable of storing and processing unstructured data
- Wasted Storage with only ~20% of data is real-time
- Licence Cost and upgrade is expensive
- Vendor dependency with proprietary solution
Apache™ Hadoop as Open Source Data Warehouse Platform:
Apache Hadoop is an open source project that provides a parallel storage and processing framework that enables customized analytical functions using commodity hardware. It scales out to clusters spanning tens to thousands of server nodes making it possible to process very large amounts of data at a fraction of the cost of enterprise data warehouses. The key is the use of commodity servers – Hadoop makes this possible by providing for replication and distribution of the nodes over multiple nodes, racks and even data centers.
Hadoop is rapidly being adopted by enterprises from leading banks and retailers to online travel and ecommerce sites in a wide range of applications.
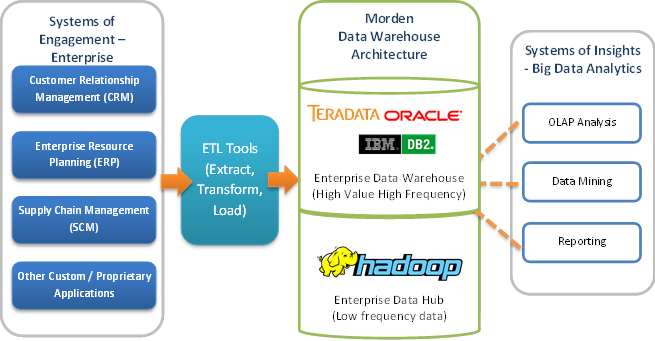
Key reasons to Augment Apache™ Hadoop with Existing Enterprise Data Warehouse:
Although Hadoop was originally developed to process unstructured data, it has quickly been embraced by enterprises to offload their data warehouse. This leads to lower cost and better performance of the data warehouse.
1. Reduce Cost
The Teradata Active Data Warehouse starts at $57,000 per Terabyte. In comparison, the cost of a supported Hadoop distribution and all hardware and datacenter costs are around $1,450/TB, a fraction of the Teradata price1. With such a compelling price advantage, it is a no brainer to use Hadoop to augment and in some cases even replace the enterprise data warehouse.
2. Off-load data processing
Hadoop provides an ideal, massively parallel platform for the extraction and transformation jobs, making these one of the first applications to be moved to Hadoop. In cases where applicable, the connectors to Hadoop that come with certain ETL tools can be used as well (although this option won’t help reduce the cost of using such tools).
3. Off-load Data Storage
In many enterprises, 80% or more of the data in a data warehouse is not actively used. As new data comes in, the volume of data in the warehouse grows, leading to increased cost as more appliances or nodes and disks are added.
Data is categorized as being hot, warm or cold based on the frequency of access. Warm and cold data are prime targets to migrate to a Hadoop cluster. Hadoop clusters are cheap and by dramatically lowering the amount of data stored in the warehouse, considerable savings can be had.
4. Backup and Recovery
By using commodity hardware and cheap disks that are replicated, Hadoop has proven to be a safe and fast backup solution. The backup solution is easy to setup and the attractive costs and recovery time make it an ideal choice for this important function.
To ensure high availability and recovery from disasters, data is backed up to geographically distributed data centers (DR site). Hadoop can be used in the DR site to keep a backup of the data warehouse.
